前面的鸢尾花案例中,我们提到了一些名词,比如样本、特征、标签、训练集、测试集及精度等,这些都属于机器学习中的专业术语,所以本节课专门介绍一下机器学习中一些基本术语。
样本:数据中的每一行被称为一个样本。
例如,鸢尾花这个分类问题中,有150个样本,也就是说有150多鸢尾花。
特征:数据中的每一列,或者说样本的属性被称为特征。
例如,鸢尾花这个分类问题中,每个样本有4个特征,分别是花萼长度、宽度,花瓣的长度、宽度。
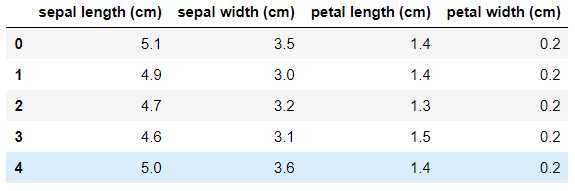
这是前面用到的鸢尾花数据,每一行代表一个样本,每一列代表一个特征。
说明:关于特征的专项课题有特征提取或者特征工程
鸢尾花有三个不同的品种,分别是setosa、versicolor和virginica。每一朵鸢尾花(每个样本),都属于其中一个品种,这里的品种在机器学习中叫作类别或者标签。
类别:在分类问题中,每一个样本都有一个类别或者标签。
二分类问题:一般常见的分类问题都是二分类问题,有两个类别,正类和反类,也可以叫负类。
多分类问题:多分类问题有三个及三个以上的类别,例如,鸢尾花分类问题就是一个三分类问题,有三个类别。
训练集、测试集:在构建机器学习模型的时候,通常是将收集好的带标签的数据分成两部分,一部分数据用于构建机器学习模型,叫做训练集(train set),其余的数据用来评估模型性能,叫做测试集(test set)。
精度:预测正确的比例,也就是正确分类数/样本总数,精度可以用来衡量模型的优劣。当然,除了精度之外,还有其他的评价指标,例如混淆矩阵、ROC曲线等。
泛化:如果一个模型能够对未知的样本数据做出准确预测,就说这个模型能够从训练集泛化到测试集。所以,我们的目标一般要构建一个泛化精度尽可能高的模型。
过拟合与欠拟合
过拟合(overfitting):如果拟合模型的时候,过分关注训练集的细节,得到了一个在训练集上表现好,但不能泛化到新的数据集上的模型,那么存在过拟合。
欠拟合(underfitting):如果模型过于简单,可能无法抓住数据的全部内容及数据中的变化,得到的模型在训练集上的表现就很差,选择过于简单的模型被称为欠拟合。
下图表示的是逻辑回归中的三种拟合状态。
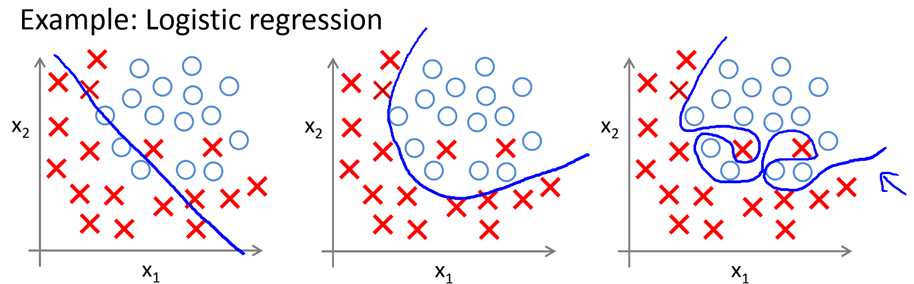
左边的图表示用一条直线(简单的模型)将这两类样本分开,可以看到,分类效果不是太好,因为很多样本没有被正确的分类。这种情况属于欠拟合,也就是选择的模型过于简单。
右边的图表示用一条复杂的曲线(复杂的模型,相对的)将这两类样本分开,我们会发现,分类效果没有问题,甚至连一些异常点也被正确地分类了,但是这种模型在一个新的数据集的表现可能不会很好,这种情况属于过拟合,即过分关注训练集的细节,导致模型过于复杂。
中间的图表示用一条合适的曲线(合适的模型)将这两类样本分开,可以看到分类效果还是不错的,尽管有一些异常点无法分类,但毕竟不多,这种拟合状态是比较理想的。
所以,一般需要在模型复杂度与训练集精度和测试集精度之间做一个权衡。
过拟合和欠拟合之间的权衡如下图所示。
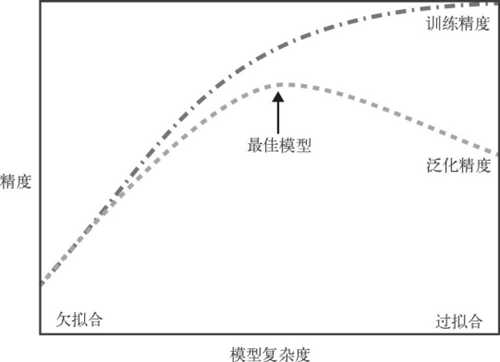
图中横坐标表示模型复杂度,纵坐标表示精度,图中两条曲线,一条代表训练集的精度,另一条代表测试集的精度(泛化精度),可以看到,随着模型复杂度的增加,训练集的精度不断增加,但增加的越来越慢,测试集的精度显示增加,到了一定程度后又会减小。当然,这个图只是描述了机器学习中的一部分情况。
通常,我们会使训练集的精度和测试集的精度都尽可能高,而且接近,以确保不会发生欠拟合或者过拟合。
好了,以上就是机器学习中的一些基本术语。