大家也许听过啤酒与尿布的故事,说是美国一家超市“沃尔玛”将啤酒与尿布这两件看似毫不相关的商品放在一起销售,结果使得啤酒与尿布的销量双双增加。事后证明这个案例确实有根据,因为美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。
作为数据分析师应该关注这背后的逻辑,这个问题本质上是分析超市商品之间的关联性。本文将对关联分析做一下介绍。
关联分析的一些概念
首先,我们需要了解一些相关的概念。
对于超市来说,每一次交易包含一些商品,如下图所示。
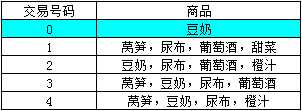
我们将每一次交易称为一个事务,一个事务包括购买行为编号和购买了哪些商品。在上图中,共有5个事务。
一次购买行为包含了多个商品,把其中的商品或者商品组合叫作项集。
例如,对于交易号码为2的交易记录来说,{豆奶,尿布}构成一个项集,{豆奶}也叫做一个项集。
接下来,为了表示某种商品或者商品的组合的受欢迎程度,引入支持度这个概念,支持度是指包含项集的事务在所有事务中所占的比例。
例如,在这5条交易记录中,有4条包含豆奶的交易记录,于是{豆奶}这个项集的支持度为4/5,再看豆奶和尿布,共有3条交易记录包含{豆奶,尿布}这个项集,于是{豆奶,尿布}的支持度:3/5。
由此可见,支持度越高,说明商品或者商品组合越受欢迎。
我们的目标就是要找出比较受欢迎的商品组合,即支持度较高的项集。
如何定义支持度较高呢?可以给支持度设置一个阈值,例如0.8,则支持度大于0.8的商品组合都属于支持度较高,引入概念频繁项集,支持度大于0.8的项集都叫作频繁项集。
分析两个商品之间的关联性,例如尿布和葡萄酒,购买尿布的有多大可能性购买葡萄酒,引入记号:{尿布}——>{葡萄酒},我们称之为关联规则,而“多大可能性”则称之为置信度。
所以,分析购买尿布的有多大可能性购买葡萄酒,则是要分析{尿布}——>{葡萄酒}这条关联规则的置信度。
那么,如何计算{尿布}——>{葡萄酒}的置信度呢?
首先,计算{尿布,葡萄酒}的支持度,即支持度({尿布,葡萄酒})=\frac{3}{5}
然后,计算{尿布}的支持度,即支持度({尿布})=\frac{4}{5}
最后,置信度=\frac{支持度({尿布,葡萄酒})}{支持度({尿布})}=\frac{3}{4}
知道了购买尿布的有多大可能性购买葡萄酒,我们还想进一步知道,尿布对于葡萄酒的销量有多大的提升,引入提升度的概念。
例如,计算{尿布}——>{葡萄酒}的提升度。
首先,计算{尿布}——>{葡萄酒}的置信度,前面已经计算出,置信度({尿布}——>{葡萄酒})=\frac{3}{4}。
然后,计算尿布的支持度,前面已经计算,支持度({尿布})=\frac{4}{5}。
则,提升度=\frac{置信度({尿布}——>{葡萄酒})}{支持度({尿布})}=\frac{15}{16}
这里,提升度小于1,说明尿布对于葡萄酒的销量没有促进作用,反而有负作用,即减少葡萄酒的销量;当提升度大于1时,说明有促进作用。
好了,以上就是关联分析中常用的一些概念。
发现频繁项集:Apriori算法
接下来,我们的目标是发现频繁项集,进一步发现关联规则。
为了便于分析,我们将每一条交易信息表示为如下矩阵的形式。
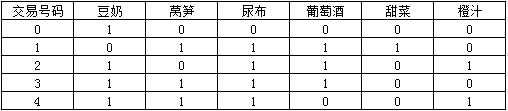
1表示此条交易中有某种商品,0表示没有。
如何发现频繁项集呢?
最直接的方式就是遍历所有商品组合,计算它们的支持度不就行了吗?
没错,可是遍历所有商品组合的效率太低了,计算量太大,而Apriori算法就是一种发现频繁项集的高效算法。
Apriori算法的核心:某个项集是频繁的,那么它的所有子集也是频繁的。
反过来说就是,如果一个项集是非频繁项集,那么它的所有超集也是非频繁项集。
运用Apriori算法的思想,我们就能去掉很多非频繁的项集,大大简化计算量。
下面来看一个关联分析的案例。
读取数据
with open('../data/groceries.csv') as fb:
contents=fb.readlines()
print(contents[:10])
运行结果:
['citrus fruit,semi-finished bread,margarine,ready soups\n', 'tropical fruit,yogurt,coffee\n', 'whole milk\n', 'pip fruit,yogurt,cream cheese,meat spreads\n', 'other vegetables,whole milk,condensed milk,long life bakery product\n', 'whole milk,butter,yogurt,rice,abrasive cleaner\n', 'rolls/buns\n', 'other vegetables,UHT-milk,rolls/buns,bottled beer,liquor (appetizer)\n', 'potted plants\n', 'whole milk,cereals\n']
以上获得的是一个列表,列表中的每一个元素是一条购买记录。
查看一下它的元素个数。
len(contents)
9835
共有9835条购买记录。
现在列表中的每一条购买记录是一个字符串,接下来,将其转换为以下列表的形式。
[['citrus fruit', 'semi-finished bread', 'margarine', 'ready soups'], ['tropical fruit', 'yogurt', 'coffee'], ['whole milk'], ['pip fruit', 'yogurt', 'cream cheese', 'meat spreads'], ['other vegetables', 'whole milk', 'condensed milk', 'long life bakery product'], ['whole milk', 'butter', 'yogurt', 'rice', 'abrasive cleaner'], ['rolls/buns'], ['other vegetables', 'UHT-milk', 'rolls/buns', 'bottled beer', 'liquor (appetizer)'], ['potted plants'], ['whole milk', 'cereals']]
转换代码如下。
transactions=[]
for content in contents:
transactions.append(content.strip().split(','))
print(transactions[:10])
[['citrus fruit', 'semi-finished bread', 'margarine', 'ready soups'], ['tropical fruit', 'yogurt', 'coffee'], ['whole milk'], ['pip fruit', 'yogurt', 'cream cheese', 'meat spreads'], ['other vegetables', 'whole milk', 'condensed milk', 'long life bakery product'], ['whole milk', 'butter', 'yogurt', 'rice', 'abrasive cleaner'], ['rolls/buns'], ['other vegetables', 'UHT-milk', 'rolls/buns', 'bottled beer', 'liquor (appetizer)'], ['potted plants'], ['whole milk', 'cereals']]
利用 Apriori 找出频繁项集
接下来,利用mlxtend库中的相关工具进行处理。
说明:mlxtend库是一个机器学习库,可以作为sklearn的补充和辅助工具,包含分类、回归、stacking分类器及关联分析的Apriori算法等。
首先,从mlxtend库导入相关函数。
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
将以上读取的transactions记录转换为one-hot编码,即0-1编码。
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
te_ary
array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, True, False],
[False, False, False, ..., True, False, False],
...,
[False, False, False, ..., False, True, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]])
可以看到,transactions记录已经被转换为0-1编码形式。
接着,将其装进DataFrame,并设置列名。
import pandas as pd
df = pd.DataFrame(te_ary, columns=te.columns_)
df.head()
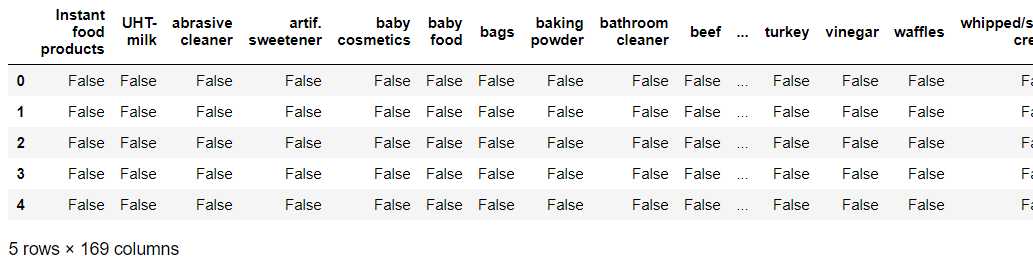
这个DataFrame,每一行代表一条购买记录,每一列代表一种商品,交易记录中有某种商品,就为True,否则为False。
可以看出,数据集中共有169种商品。
接下来,利用mlxtend库中的Apriori工具找出频繁项集。
freq = apriori(df, min_support=0.05, use_colnames=True)
freq
说明:这里设置的条件是找出支持度大于0.05的项集(商品组合)。
support itemsets
0 0.052466 (beef)
1 0.080529 (bottled beer)
2 0.110524 (bottled water)
3 0.064870 (brown bread)
4 0.055414 (butter)
5 0.077682 (canned beer)
6 0.082766 (citrus fruit)
7 0.058058 (coffee)
8 0.053279 (curd)
9 0.063447 (domestic eggs)
10 0.058973 (frankfurter)
11 0.072293 (fruit/vegetable juice)
12 0.058566 (margarine)
13 0.052364 (napkins)
14 0.079817 (newspapers)
15 0.193493 (other vegetables)
16 0.088968 (pastry)
17 0.075648 (pip fruit)
18 0.057651 (pork)
19 0.183935 (rolls/buns)
20 0.108998 (root vegetables)
21 0.093950 (sausage)
22 0.098526 (shopping bags)
23 0.174377 (soda)
24 0.104931 (tropical fruit)
25 0.071683 (whipped/sour cream)
26 0.255516 (whole milk)
27 0.139502 (yogurt)
28 0.074835 (whole milk, other vegetables)
29 0.056634 (whole milk, rolls/buns)
30 0.056024 (yogurt, whole milk)
从结果看到,共有31个项集满足条件。
找出关联规则
最后,利用mlxtend库中的association_rules工具找出关联规则。
rules = association_rules(freq, min_threshold=0.1)
rules
这里设置的条件是找出置信度大于0.1的关联规则。
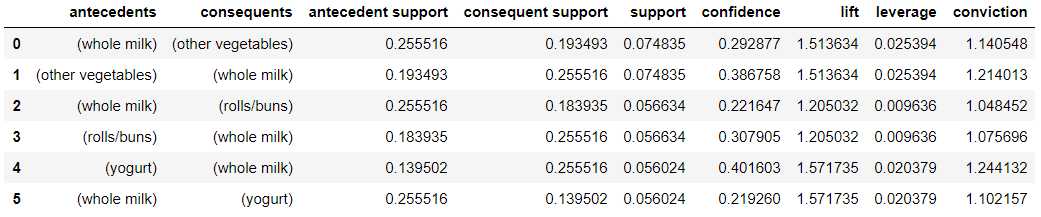
可以看到,共有6条关联规则满足条件。
关于以上结果每一列的说明如下。
- antecedents:规则先导项
- consequents:规则后继项
- antecedent support:规则先导项支持度
- consequent support:规则后继项支持度
- support:规则支持度 (前项后项并集的支持度)
- confidence:规则置信度 (规则置信度:规则支持度support / 规则先导项)
- lift:规则提升度,表示含有先导项条件下同时含有后继项的概率,与后继项总体发生的概率之比。
- leverage:规则杠杆率,表示当先导项与后继项独立分布时,先导项与后继项一起出现的次数比预期多多少。
- conviction:规则确信度,与提升度类似,但用差值表示。
以上就是关联分析的理论与实战。