机器学习是Machine Learning(ML)的中文翻译,是指让计算机具备像人一样的学习能力,从海量的数据中获取新的知识或者技能。
它是计算机科学、数学和工程技术等多个领域的交叉学科。
近年来,机器学习已经应用到日常生活的方方面面,大致分为四个方向。
- 推荐系统:例如个人性化新闻推荐、商品推荐、个性化广告等。
- 自然语言处理(NLP):例如文本分类、语音识别、聊天机器人等。
- 计算机图像识别(CV):例如人脸识别、车辆识别、物体检测等。
- 数据挖掘(DM):例如金融机构预测是否逾期、超市购物篮分析及客户分群管理等。
机器学习问题分为两类:监督学习和无监督学习。
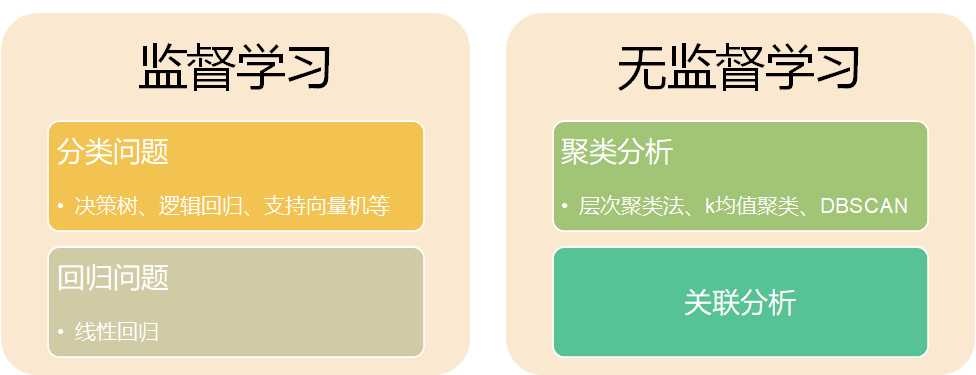
监督学习包括分类和回归,常见的决策树、逻辑回归、支持向量机等主要用解决分类问题,回归就是常见的线性回归。
无监督学习包括聚类分析和关联分析,聚类分析包括层次聚类法、K均值聚类法和DBSCAN(一种基于密度的分类方法),关联分析主要用于商品购物篮分析。
监督学习
监督学习(supervised learning)主要用于解决分类问题,例如金融机构预测一个用户是/否会逾期。
对于监督学习算法来说,给定的样本数据必须包括两部分:特征(X)和类别(y)。算法可以样本的特征去预测类别(标签)。
例如,给定一封邮件,判断是/否为垃圾邮件,已知的样本数据需要包括电子邮件的特征和类别(标签)。
例如,基于医学影像判断肿瘤是/否为良性,已知的样本数据需要包括影像的特征和类别。
例如,检测信用卡交易是/否存在欺诈行为,已知的样本数据需要包括信用卡交易记录的特征和类别。
监督学习中还有一类问题,线性回归(Linear Regression),主要用于预测一个连续数值,给定的样本数据包括自变量(X:x1,x2,x3,…)和因变量(y),只不过都是数值型。
例如,根据教育水平x1、年龄x2和居住地x3等,预测一个人的年收入y。
无监督学习
无监督学习(unsupervised learning)主要用于聚类、降维等,例如常见的K均值聚类分析、主成分分析(PCA)等。
对于无监督学习算法来说,给定的样本数据只有样本的特征(X),而没有类别(标签)。
例如,用户分群管理,已知的样本数据只有用户的特征,如消费金额、消费频次等,需要根据用户的特征将用户分为不同的类别(类别数未知)。
机器学习的一般步骤
对于一个机器学习问题来说,一般分为三步:
- 分析问题,数据探索及预处理
- 选择合适的模型,利用训练集训练模型
- 模型评估及使用,利用测试集评估模型
好了,我们已经了解了机器学习,下一节将会学习一个经典的机器学习案例。