之前说过,机器学习中主要有两类算法,监督学习和无监督学习。
我们之前学习的K近邻算法、逻辑回归、决策树及支持向量机等都属于监督学习算法,主要用于解决分类问题,这类问题的样本数据包含两部分:样本特征X和类别标签y。还有一类问题,它的样本数据只有特征X,没有类别标签,需要用到聚类算法,例如K均值聚类,这种算法称为无监督学习算法。
无监督学习算法包括聚类算法、主成分分析等,主要用于聚类、降维。
例如,用户分群管理,已知的样本数据只有用户的特征,如消费金额、消费频次等,需要根据用户的特征将用户分为不同的类别(类别事先未知)
再比如,下表是同一批客户对经常光顾的五座商厦在购物环境和服务质量两方面的平均评分。现希望根据这批数据将五座商厦分类。
| 编号 | 购物环境 | 服务质量 |
|---|---|---|
| A | 73 | 68 |
| B | 66 | 64 |
| C | 84 | 82 |
| D | 91 | 88 |
| E | 94 | 90 |
从以上表格可以看到,这5个样本只知道他们的特征,购物质量的评分和服务质量的评分,没有类别标签,我们需要根据这两个特征对样本进行分类,之前的分类算法,如逻辑回归、决策树等已经不适用于这种问题了,我们需要用到聚类分析来处理这种问题。
首先,我们来看一下聚类分析的基本原理。
聚类分析基本原理
聚类分析的特点是事先不知道所研究的问题应分为几类,也不知道观测到的个体的具体分类情况,需要按照性质上的亲疏程度在没有先验知识的情况下进行自动分类,产生分类结果。
如何理解呢?
例如,根据客户(用户)的消费特征,如消费金额、消费频次、最近一次消费距现在的时长等,将客户分为不同的类别,事先并不知道客户的类别标签及类别特征。
聚类分析有两种常见的聚类分析方法,一种是层次聚类法,另外一种是K均值聚类法。
首先,来看下层次聚类法。
层次聚类法
层次聚类法主要分为以下三步:
1、开始每个样本自成一类,有几个样本就有几个类。
2、计算各个类之间的距离,每次合并距离最近的两个类。
3、重复步骤2,直至所有样本都合并为一个类。
这里面涉及到距离的计算,距离有很多种,这里以欧氏距离为例说明。
欧氏距离:
EUCLID(x,y)=\sqrt{\sum_{i=1}^p(x_i-y_i)^2}
下面,来看一个小的例子,商厦分类。
下表是同一批客户对经常光顾的五座商厦在购物环境和服务质量两方面的平均评分。现希望根据这批数据将五座商厦分类。
| 编号 | 购物环境 | 服务质量 |
|---|---|---|
| A | 73 | 68 |
| B | 66 | 64 |
| C | 84 | 82 |
| D | 91 | 88 |
| E | 94 | 90 |
首先,计算出各样本两两之间的距离。
例如,计算样本A和B之间的距离
D(A,B)=\sqrt{(73-66)^2+(68-64)^2}=8.06
按照类似的方式,可以将所有样本之间的距离都计算出来,得到距离矩阵。
D_0=\begin{bmatrix}
& A&B&C&D&E \\
A&0&\quad&\quad&\quad \\
B&8.06&0 &\quad &\quad \\
C&17.80& 25.46&0 &\quad \\
D&26.91& 34.66&9.22&0 \\
E&30.41& 38.21&12.81&3.61&0
\end{bmatrix}
D,E之间的距离最小,因此将D,E合并为一个新类,记为CL4,CL4={D,E}
接着计算各类之间的距离矩阵
D_1=\begin{bmatrix}
&A&B &C &CL4={D,E} \\
A&0&\quad&\quad&\quad \\
B&8.06 &0 &\quad &\quad \\
C&17.80&25.46&0&\quad \\
CL4={D,E}&26.91&34.66&9.22&0
\end{bmatrix}
A,B之间的距离最小,因为将A,B合并为一个新类,记为CL3,CL3={A,B}
接着计算各类之间的距离矩阵
D_2=\begin{bmatrix}
&CL3&C&CL4={D,E} \\
CL3&0&\quad&\quad \\
C&17.80&0&\quad \\
CL4={D,E}&26.91&9.22&0
\end{bmatrix}
C,CL4之间的距离最小,因为将C,CL4合并为一个新类,记为CL2,CL2={C,CL4}
D_2=\begin{bmatrix}
&CL3&CL2 \\
CL3&0&\\
CL2&17.80 &0 &
\end{bmatrix}
最后,将CL3和CL2合并为CL1。至此,并类完成。
将上述聚类过程用一个图来表示,即谱系聚类图,如下图所示。
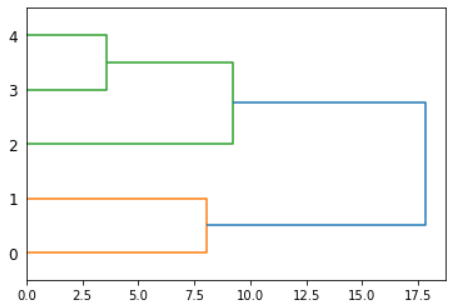
有了谱系聚类图,就很容易得出聚类分析的结果。
例如,如果要分为两类,只需要这样“切一刀”,如下图所示。
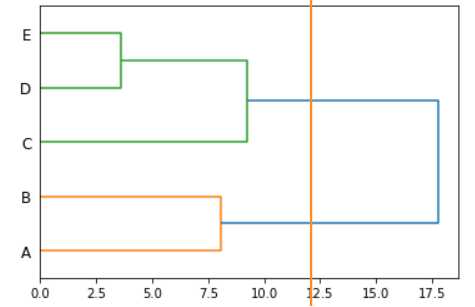
从上图可以看到,样本{A,B}属于一个类别,样本{C,D,E}属于一个类别。
直观上也很好理解,其中,样本A,B的两个指标的评分较低,可以归为一类,样本C,D,E的评分较高,当然归为一类。所以,就把所有样本分成了两个类别。
如果要分为三类,只需要这样“切一刀”,如下图所示。
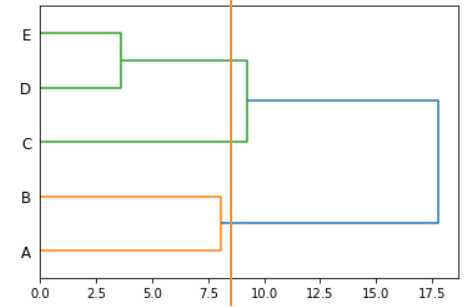
从上图可以看出,样本{A,B}属于一类,样本{C}属于一类,样本{D,E}属于一类。
直观上也可以理解,其中,样本{A,B}的评分最高,样本{C}的评分居中,样本{D,E}的评分最高。
除了层次聚类法之外,还有一种聚类分析算法也很常用,就是K均值聚类法。
K均值聚类算法
K均值聚类英文名称是k-means clustering,所以叫作K均值聚类法。这里的k是指聚类类别数,例如,如果想将样本分为3类,则k=3,如果分为6类,则k=6。
K均值聚类法分为以下三步。
1、确定聚类类别数、初始聚类中心。
2、通过计算每一个样本与聚类中心之间的距离,将样本归到距离最近的类中。
3、重新计算每个类的聚类中心,重复这样的过程,直到每个样本都被归入类中。
还是以前面用过的商厦分类问题为例。
首先,确定聚类类别数和初始聚类中心,这里假设需要分为3类,随机选取三个样本B,C,E,作为初始聚类中心。
接着,计算出其余样本与所有聚类中心之间的距离(欧氏距离)。
D_0=\begin{bmatrix}
& A&B&C&D&E \\
A&0&\quad&\quad&\quad \\
B&8.06&0 &\quad &\quad \\
C&17.80& 25.46&0 &\quad \\
D&26.91& 34.66&9.22&0 \\
E&30.41& 38.21&12.81&3.61&0
\end{bmatrix}
观察聚类中心以外的其它样本,目前只有两个样本,A和D。
其中,样本A离B最近,所以将其归入样本B所在的类,此时B所在的类的聚类中心为A与B的平均,也就是说聚类中心发生了改变。
样本D离C最近,所以将其归入样本C所在的类,同上,样本C所在的类的聚类中心也发生了改变。
至此,得到三类,C1={A,B},C2={C},C3={D,E}
直观上很好理解,其中,样本{A,B}的评分最高,样本{C}的评分居中,样本{D,E}的评分最高,所以分为这三类。
虽然这里的样本比较少,但是大家可以直观上理解K均值聚类法的聚类过程。
如果有很多个样本,手动去计算距离则不合适,需要借助于计算机来求解。
这里再展示一张K均值聚类法的流程示意图。
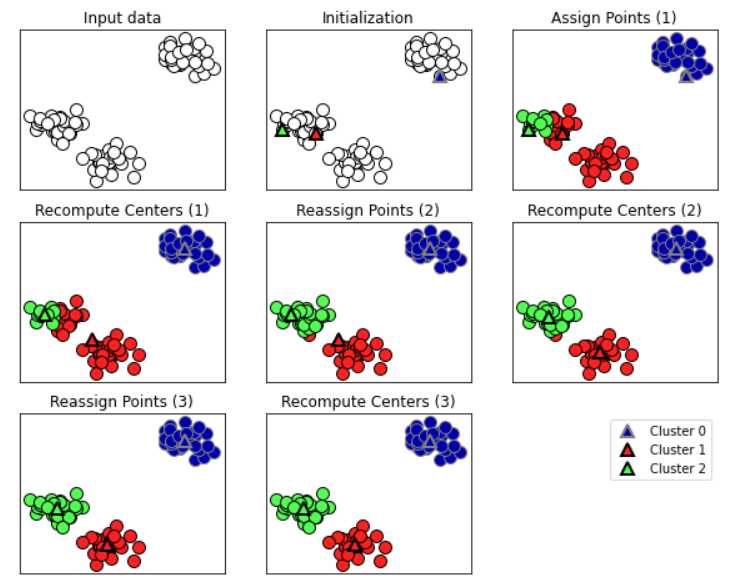
上图中,第一个图表示初始样本数据。
第二个图表示随机选取了三个初识聚类中心,也说明希望分为三类,这三个初识聚类中心代表三个类。
第三张图表示经过一轮距离判断后,将离这三个初识聚类中心最近的样本分到这三个类中,图中的三角形状表示初识聚类中心。
第四张图,表示聚类中心发生了变化,见图中的三角形状。
第五张图,表示将离这三个聚类中心(三角形状)最近的样本归入这三个类中。
第六张图,表示聚类中心发生了变化。
第七张图,表示继续将离这三个聚类中心(三角形状)最近的样本归入这三个类中。
第八张图,表示聚类中心发生了变化,不明显,此时聚类完成。
从图中可以看到,最终的分类结果也符合预期,即这三个簇各自成为一个类,很合理。
K均值聚类法的局限性
例如有以下形状的样本数据,月牙形,上半部分是一个类别,下半部分是另一个类别。
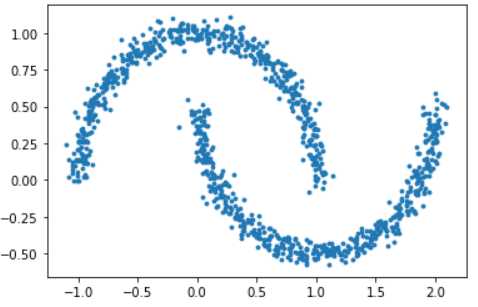
如果用K均值聚类法,聚类结果如下图所示。
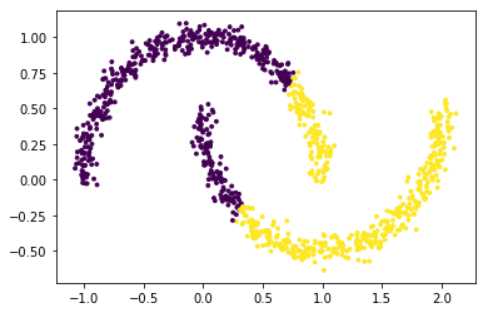
假设K=2,K均值聚类法会随机选取选取两个初始聚类中心,然后遍历其余样本,将距离聚类中心最近的样本逐个加入距离最近的类中,最终会呈现出以上的效果。
但是,这种分类结果有问题。
如果,我们基于密度的思想,将距离较近(密度较大)的样本都归为一类,也就是说聚在一起的样本划分为一个类别,在这种月牙形状的数据中,上半部分的密度较大,归为一类,下半部分的密度也较大,也归为一类,就可以解决这个问题。
这种基于密度的聚类法算法就是DBSCAN。
DBSCAN算法
DBSCAN是Density-Based Spatial Clustering of Applications with Noise的缩写,中文翻译为:具有噪声的基于密度的聚类方法。
DBSCAN算法基本原理
它是一种基于密度的空间聚类算法,这个算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,我们将样本点形成的类叫作簇。
DBSCAN算法大致是这样的:
设定一个聚类半径(阈值),只要距离小于该半径的样本点都归为一类,同时,设定一个密度,也就是最少要圈住的样本点的个数,避免离群点成为一类。
两个关键参数
所以,DBSCAN算法有两个参数:半径和密度。
1、半径
半径表示样本点的距离阈值,小于该阈值的样本点都圈为一类,所以,半径大,圈住的样本点就多,簇的个数就少;反之,半径小,圈住的样本点就少,簇的个数就多。
如果将半径设置得较大,很可能所有的样本都被归为一个簇,这就失去了聚类的意义了,关键是要找到突变点。例如,这种月牙形的样本数据,对于上半部分来说,下半部分的点就属于突变点,因为这些点到上半部分的距离突然增大了,所以半径要设置得小于这两部分的最小距离,这样才能将这两部分分开。
2、密度
密度表示圈住的样本点个数的最小值,通常设置一个较小的值即可。
我们可以通过sklearn来使用DBSCAN,在sklearn中,参数eps表示半径,参数min_samples表示密度。
DBSCAN评估:轮廓系数
对于某个样本来说,
该样本与其所在簇内其他样本的平均距离,记为a_i
该样本与其他簇内样本的平均距离b_i
则这个样本的轮廓系数为:
s_i=\frac{b_i-a_i}{\max(a_i,b_i)}
所以,聚类分析的轮廓系数为所有样本的轮廓系数的均值:
s=\frac{1}{m}\sum_{i=1}^m{s_i}
轮廓系数取值范围为[-1,1],取值越接近1则说明聚类性能越好,相反,取值越接近-1则说明聚类性能越差。